NeurIPS 2024 - 云端目标检测大模型自适应首篇!

发布于:
修改于:
关键词: 云端目标检测大模型自适应、知识传播、知识分离、知识蒸馏、梯度方向对齐
转载自: 原文地址
Paper | Code | Project | Slides | Poster | Zhihu | REDnote
摘要
我们提出了一个有趣且符合时代潮流的问题——云端目标检测大模型自适应(Cloud Object Detector Adaptation, CODA),其中目标域利用由云端目标检测大模型提供的检测结果训练目标域检测器。尽管云端大模型具有强大的泛化能力,但在特定目标域中仍然无法实现无错误的检测。因此,我们提出了一种新的云端目标检测大模型自适应方法,即通过整合不同源知识的COIN(Cloud Object detector adaptation method by Integrating different source kNowledge),其核心思想是引入一个公开的视觉-语言模型(CLIP),通过自促进梯度方向对齐来蒸馏正知识并优化负知识以实现自适应。为此,知识传播、分离和蒸馏被经依次进行。1.知识传播首先将云端检测器和CLIP模型的知识结合起来,用于在目标域中初始化目标域检测器和CLIP检测器。2.知识分离使用分而治之的策略将CLIP检测器和云端检测器的检测结果相匹配,并将它们分为一致的、不一致的和私有的三部分,以便逐个进行知识蒸馏。3.知识蒸馏逐个击破,其中一致和私有的检测结果直接用于训练目标域检测器,而不一致的检测结果则首先被一个提出的一致性知识生成网络进行深度融合,然后再被蒸馏入目标域检测器。由于一致检测的梯度方向提供了指向最优目标域检测器的方向,因此我们使用它作为监督信号,将不一致检测的梯度方向与它对齐来训练该网络。实验结果表明,所提出的COIN方法达到了最先进的性能水平。
云端目标检测大模型自适应(CODA)与其他相近问题设定之间的区别,以及所提出的方法(COIN)的整体概括图1所示。得益于云端大模型,开放的目标域场景和类别都能够被学习!以后想要在目标域训练模型,再也不需要去费力地找一个需要与它相似的源域了!
目前,IDEA-Research已经正式开放了Grounding DINO 1.5的云端API,为我们的工作提供了更为实用的应用场景。并且,我们已经在Github开源代码中提供了直接使用Grounding DINO 1.5的云端API作为云模型的代码,欢迎大家点赞关注!
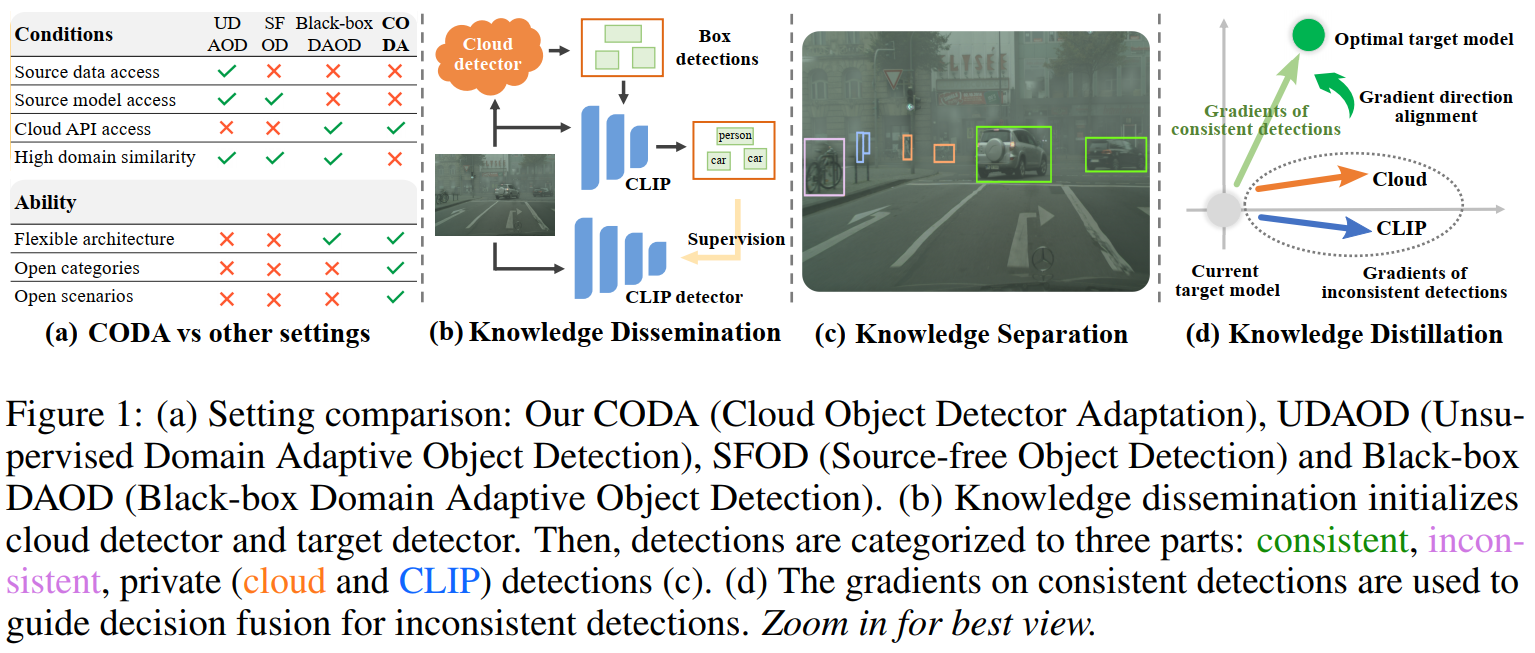
云端目标检测大模型自适应的详细定义
算法细节
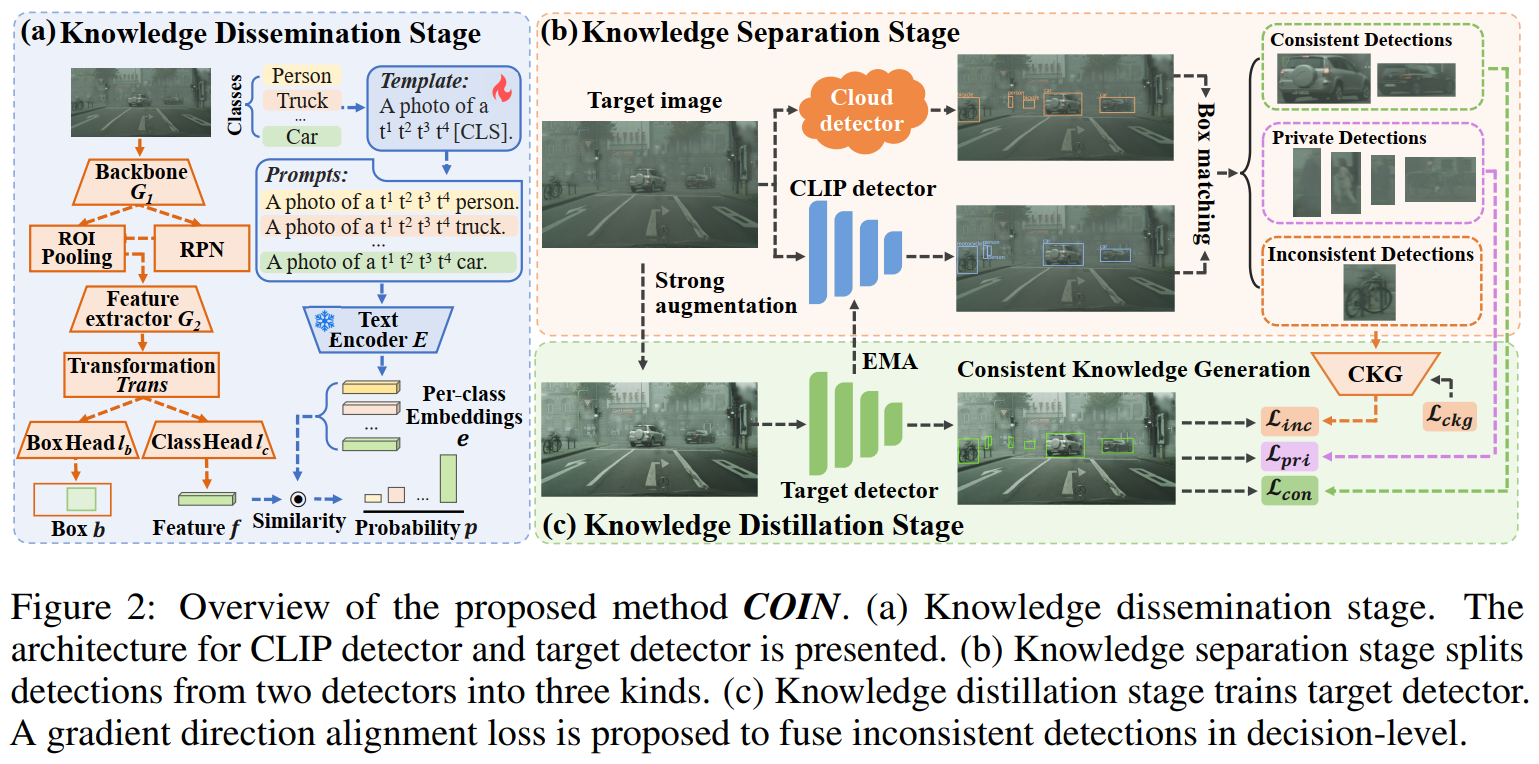
所提出的COIN方法引入了视觉-语言模型CLIP[1]来辅助自适应一个可以任意选择的云端目标检测大模型(如GDINO[2])。如图2所示,该方法包含三个阶段:知识传播、知识分离和知识蒸馏。
在知识传播阶段,首先分别收集云端检测器和CLIP的检测结果。以GDINO为例,它的检测框和CLIP的分类结果被用来预训练CLIP检测器和初始化目标域检测器,如图1(b)所示。如图2(a)所示,预训练时,对 CLIP 检测器同时进行提示学习(prompt learning),使CLIP的知识进一步传播并自适应到目标域。
在知识分离阶段,如图2(b)所示,首先获取来自云端检测器和 CLIP 检测器的检测结果,其次通过匹配将他们分为一致、不一致和私有三类。
在知识蒸馏阶段,我们采用了Mean-Teacher框架,其中将云端检测器和CLIP检测器视为两个教师模型,而目标域检测器视为学生模型。为了增强模型的鲁棒性,学生模型接收经过强增强处理的目标域图像输入,一致和私有检测结果则直接作为伪标签使用。对于不一致的检测结果,我们设计了一个一致性知识生成网络(Consistent Knowledge Generation network, CKG)来在决策层面进行融合;同时提出了一种自促进梯度方向对齐损失来优化 CKG,使得目标域检测器和CKG相互更新。融合的知识通过指数移动平均(Exponential Moving Average,EMA)机制不断更新CLIP检测器,从而实现更好的知识融合。
第一阶段:知识传播
为了便于后续的分离和蒸馏,我们首先通过知识传播预训练一个CLIP检测器,该步骤借助了云端检测器和CLIP模型的知识——同时利用云端模型的检测框和CLIP对这些框的分类结果作为标签来训练。具体的损失函数如下:
第二阶段:知识分离
就像同时抛掷两枚硬币(COIN)一样,云端检测器和CLIP检测器的检测结果由于各自预训练数据的不同,既可能存在一致性,也可能出现冲突。显然,一致的检测结果可以作为可靠的真实值使用,而冲突则会为知识融合带来挑战。为了合理地将这两者的知识整合到目标域检测器中,我们采用了“分而治之”的策略,本小节为“分”,而下一小节则为“合”,具体如下:
从公式中可以看出,一致性检测代表匹配且预测类别相同的检测结果;不一致性检测代表匹配但预测类别不同的检测结果;私有检测代表没有匹配的检测结果。对于一致性检测和不一致性检测中的匹配框,我们基于概率加权将他们融合:
第三阶段:知识蒸馏
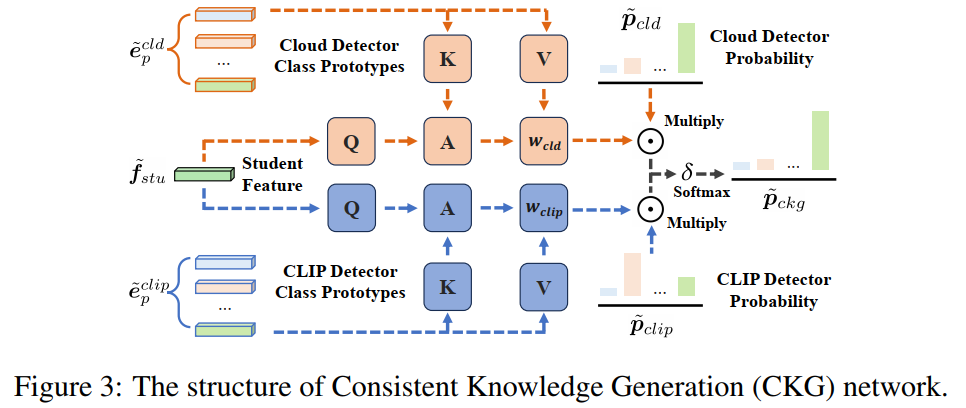
该阶段分别将以上三种检测结果合理地融合到目标域检测器中;Mean-Teacher框架和EMA参数更新机制被使用,将融合知识向CLIP检测器流动,从而实现更好的知识融合。
对于一致性检测和私有检测,一致性检测被用当作真实标签用于监督训练,私有检测被当作候选框输入网络中,并仅通过蒸馏分类概率实现知识融合:
除了梯度对齐外,CKG网络还要保证能够在一致性检测上输出正确的预测结果,因此训练CKG网络的总损失如下:
CKG网络与目标域检测器迭代更新,首先CKG网络基于目标域检测器的梯度优化更新,随后目标域检测器又通过CKG网络输出的预测结果优化更新:
算法流程如如图4所示:

实验
基准数据集的性能
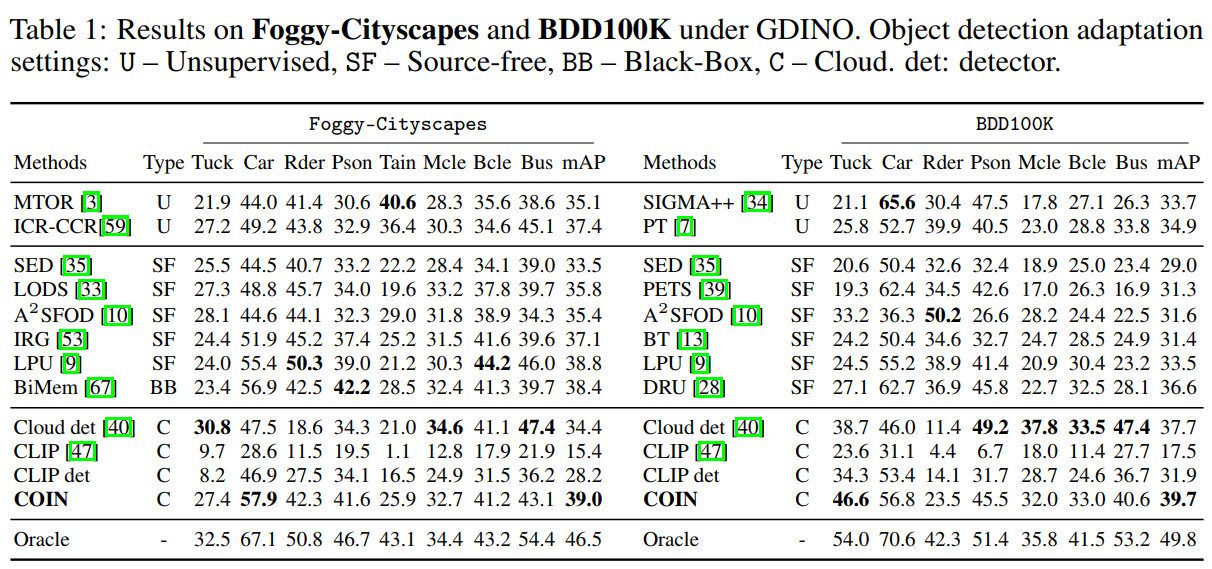
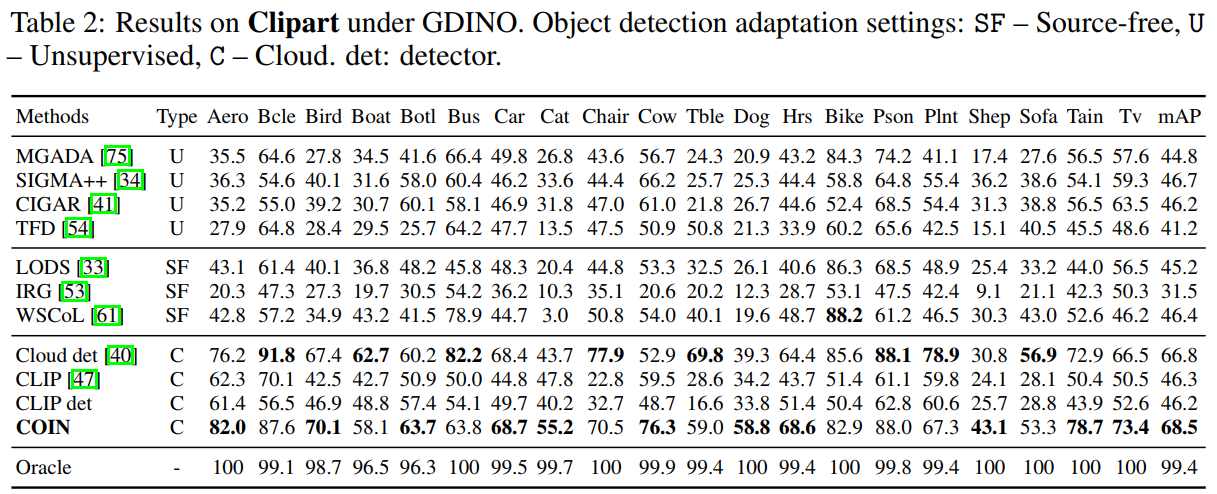
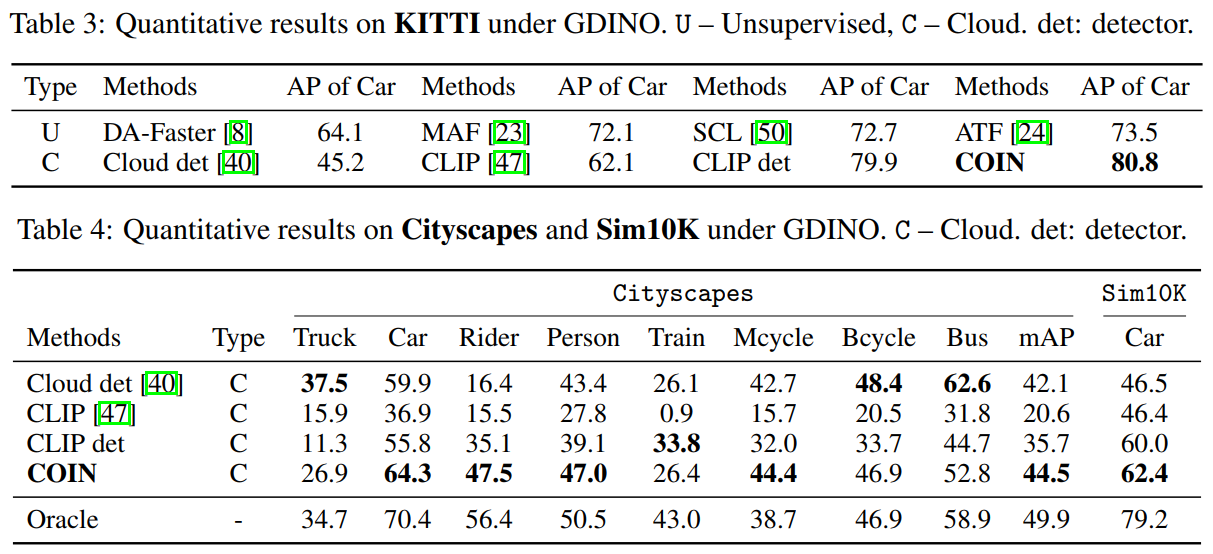
我们报告了常用的六个数据集:Foggy-Cityscapes、BDD100K、KITTI、Cityscapes、Sim10K以及Clipart的实验结果。由于这是首篇关于CODA的工作,因此我们将COIN与UDAOD、SFOD以及Black-box DAOD的方法对比,且使用GDINO作为云端目标检测大模型,具体结果如图5-7所示,其中CLIP代表使用云端检测器的框以及CLIP模型的分类结果;CLIP检测器代表经过知识传播阶段预训练后输出的CLIP检测器。
消融实验
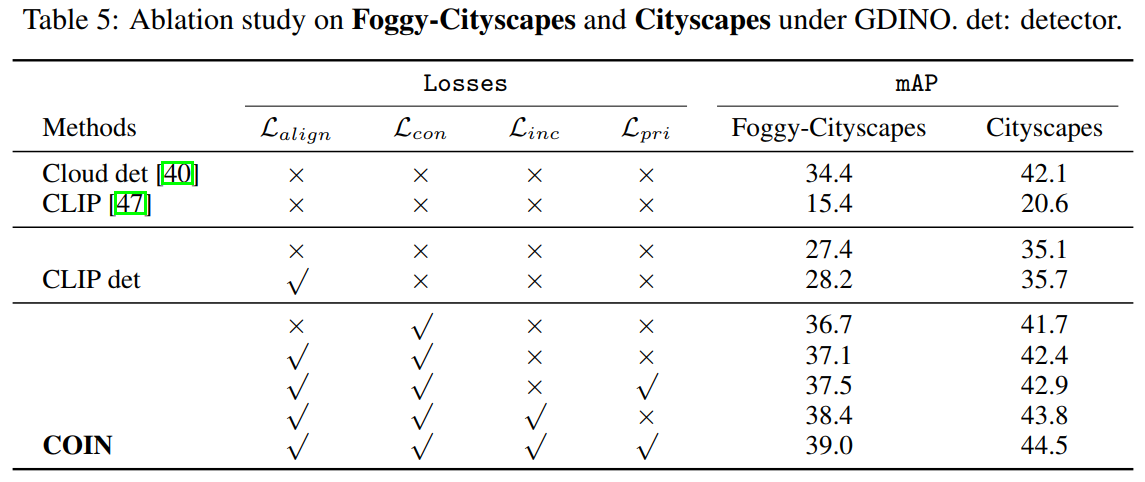
我们针对每一个损失函数以及不同的训练阶段进行了消融试验,具体结果如图8所示。可以看到,每个部件都为整体结果发挥着积极的作用。
不同决策级融合策略性能对比
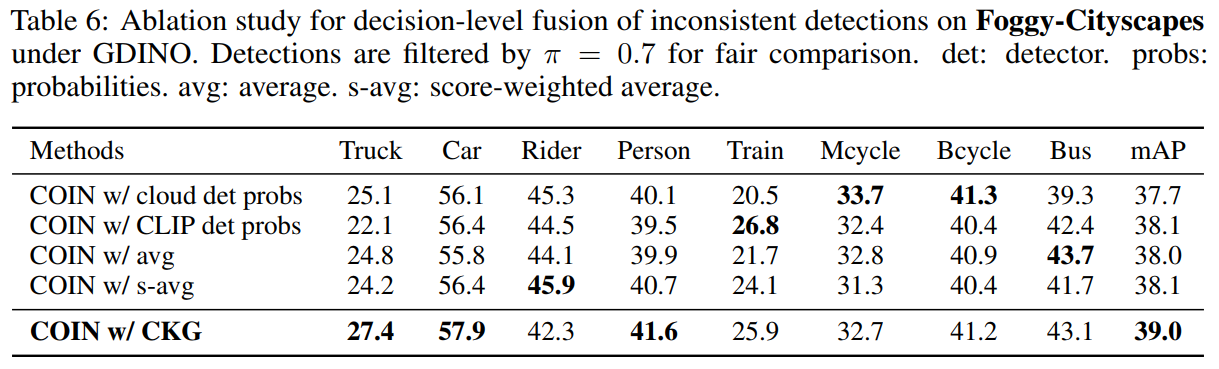
为了进一步验证我们决策级融合的有效性,我们将提出的COIN与其他四种策略进行了对比,结果如图9所示,单独使用CLIP检测器达到了38.1%的mAP,这是因为它的EMA更新机制使它融入了来自于云端检测器的知识。而使用CKG网络则取得了最优的效果,这证明了我们提出的决策级融合的有效性。
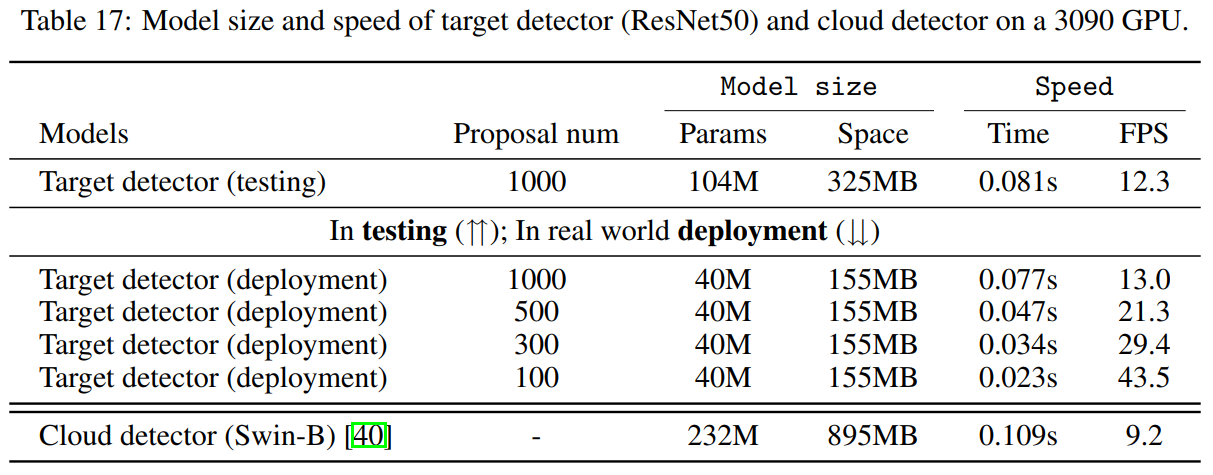
模型检测速度对比
我们对比了在测试阶段和实际部署阶段目标域检测器与云端检测器的检测速度,如图10所示。在实际部署时,目标域检测器的文本编码器可以被丢掉,直接使用语义嵌入计算分类概率以增加计算速度。从图中可以看到,相比于云端检测器,即使在不考虑API请求时延的情况下,我们的检测器依旧完胜。
补充
请注意,CODA 旨在将云检测器自适应(或者说蒸馏)到目标域,因此 CLIP 的使用是可选的。为了解决 CODA 问题,我们的方法 COIN 采用了 CLIP;然而,这并不意味着 CODA 问题设置假设存在本地(CLIP 或源域)检测器,更不假设CLIP一定要被使用。请注意区分。
总结
我们提出了一个适用于当前潮流、适用于云端大模型的、具有广阔应用前景的问题——云端目标检测大模型自适应(CODA)。为此,我们提出了一种新颖的COIN方法,并采用了“分而治之”的策略来解决该问题。通过引入一个开放的辅助模型(CLIP)来帮助模型自适应,并且通过巧妙地整合不同源知识,实现了“1+1>2”的效果。
提出了一种新颖的决策级融合策略。通过设计梯度方向对齐损失,利用一致性检测结果,以一种合理且自促进的方式来融合冲突检测结果。
针对CLIP检测器和目标域检测器进行了不同的提示学习。对于CLIP检测器,通过将语义嵌入与CLIP的视觉特征类别原型对齐来进行训练;而对于目标域检测器,由于其结合了不同源知识,因此使用基于一致性检测结果的类别原型进行学习。
引用
[1] Learning transferable visual models from natural language supervision.
[2] Grounding dino: Marrying dino with grounded pre-training for open-set object detection.
感谢阅读!如果觉得本文有帮助,请为我们的开源代码点个⭐️吧~