Source-Free Object Detection by Learning to Overlook Domain Style
Shuaifeng Li, Mao Ye, Xiatian Zhu, Lihua Zhou, Lin Xiong
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), ORAL
Published:
Key Words: Source-Free Object Detection; Style Enhancement; Overlooking Style
Abstract
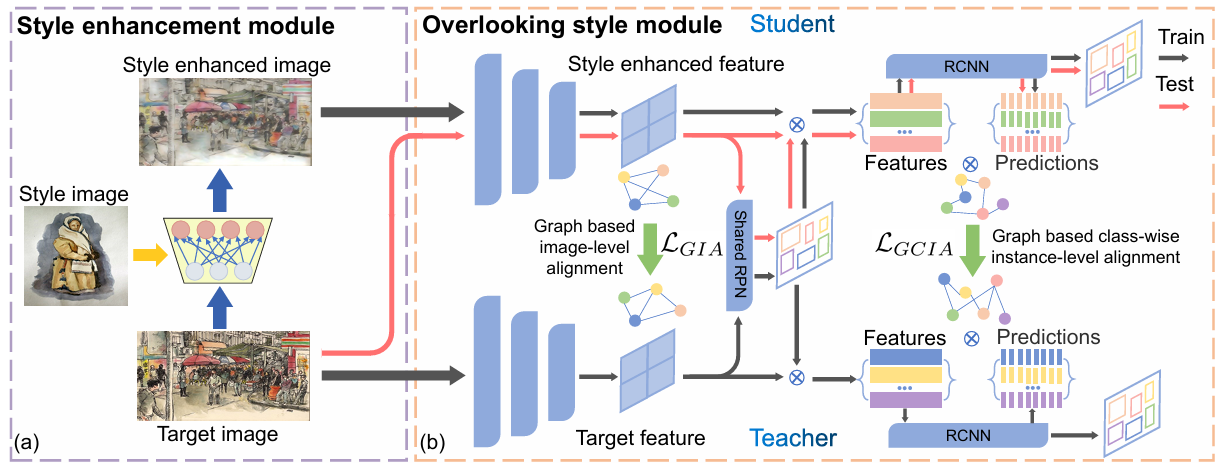
Source-free object detection (SFOD) needs to adapt a detector pre-trained on a labeled source domain to a target domain, with only unlabeled training data from the target domain. Existing SFOD methods typically adopt the pseudo labeling paradigm with model adaption alternating between predicting pseudo labels and fine-tuning the model. This approach suffers from both unsatisfactory accuracy of pseudo labels due to the presence of domain shift and limited use of target domain training data. In this work, we present a novel Learning to Overlook Domain Style (LODS) method with such limitations solved in a principled manner. Our idea is to reduce the domain shift effect by enforcing the model to overlook the target domain style, such that model adaptation is simplified and becomes easier to carry on. To that end, we enhance the style of each target domain image and leverage the style degree difference between the original image and the enhanced image as a self-supervised signal for model adaptation. By treating the enhanced image as an auxiliary view, we exploit a student-teacher architecture for learning to overlook the style degree difference against the original image, also characterized with a novel style enhancement algorithm and graph alignment constraint. Extensive experiments demonstrate that our LODS yields new state-of-the-art performance on four benchmarks.
Supplement
We use the standard Faster R-CNN as the teacher and student. For PASCAL VOC to Clipart and PASCAL VOC to Watercolor, we use Resnet101 as our backbone. For Cityscapes to Foggy-Cityscapes and KITTI to Cityscape, we use VGG16 (without batchnorm) as our backbone.
Note that for the Foggy-Cityscapes dataset, we use the foggy level of 0.02. For Clipart dataset, we use all 1K images for both training and testing.
Cite this paper
@InProceedings{Li_2022_CVPR,
author = {Li, Shuaifeng and Ye, Mao and Zhu, Xiatian and Zhou, Lihua and Xiong, Lin},
title = {Source-Free Object Detection by Learning To Overlook Domain Style},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {8014-8023}
}