Cloud Object Detector Adaptation by Integrating Different Source Knowledge
Shuaifeng Li, Mao Ye, Lihua Zhou, Nianxin Li, Siying Xiao, Song Tang, Xiatian Zhu
The Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS)
Published:
Key Words: Cloud Object Detector Adaptation; Gradient Direction Alignment
Abstract
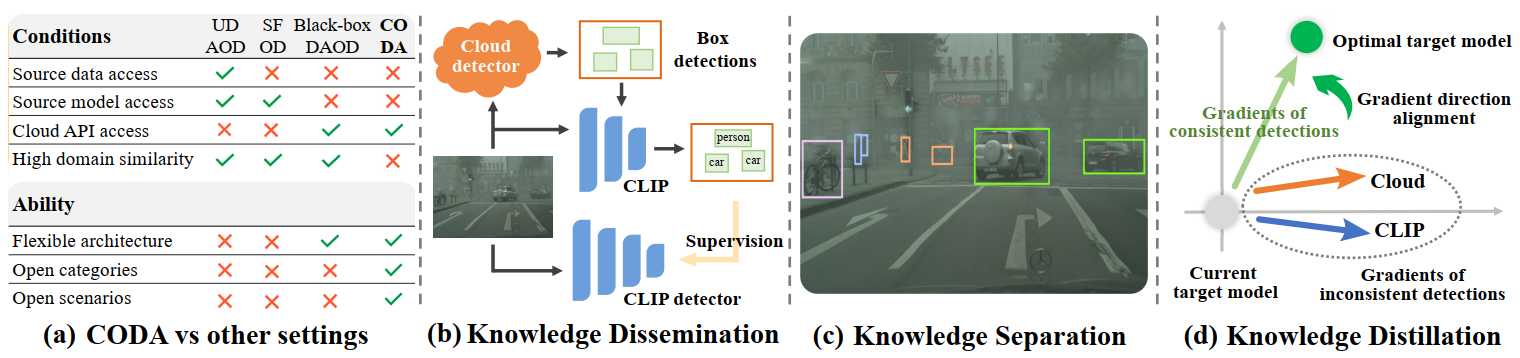
We propose to explore an interesting and promising problem, Cloud Object Detector Adaptation (CODA), where the target domain leverages detections provided by a large cloud model to build a target detector. Despite with powerful generalization capability, the cloud model still cannot achieve error-free detection in a specific target domain. In this work, we present a novel Cloud Object detector adaptation method by Integrating different source kNowledge (COIN). The key idea is to incorporate a public vision-language model (CLIP) to distill positive knowledge while refining negative knowledge for adaptation by self-promotion gradient direction alignment. To that end, knowledge dissemination, separation, and distillation are carried out successively. Knowledge dissemination combines knowledge from cloud detector and CLIP model to initialize a target detector and a CLIP detector in target domain. By matching CLIP detector with the cloud detector, knowledge separation categorizes detections into three parts: consistent, inconsistent and private detections such that divide-and-conquer strategy can be used for knowledge distillation. Consistent and private detections are directly used to train target detector; while inconsistent detections are fused based on a consistent knowledge generation network, which is trained by aligning the gradient direction of inconsistent detections to that of consistent detections, because it provides a direction toward an optimal target detector. Experiment results demonstrate that the proposed COIN method achieves the state-of-the-art performance.
Supplement
Please note that CODA aims to adapt/distill the cloud detector to target domain, e.g., a target detector, so the use of CLIP is optional. To address the CODA problem, our method, COIN, employs CLIP; however, this does not imply that the CODA problem setting assumes the existence of a local (CLIP or source domain) detector, nor does it assume that CLIP must necessarily be used. Please keep this distinction in mind.
Cite this paper
@inproceedings{NEURIPS2024_2ce4f0b8,
author = {Li, Shuaifeng and Ye, Mao and Zhou, Lihua and Li, Nianxin and Xiao, Siying and Tang, Song and Zhu, Xiatian},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Globerson and L. Mackey and D. Belgrave and A. Fan and U. Paquet and J. Tomczak and C. Zhang},
pages = {25251--25283},
publisher = {Curran Associates, Inc.},
title = {Cloud Object Detector Adaptation by Integrating Different Source Knowledge},
url = {https://proceedings.neurips.cc/paper_files/paper/2024/file/2ce4f0b8e24c45318352068603153590-Paper-Conference.pdf},
volume = {37},
year = {2024}
}